Blog article
How To Avoid Duplicate Content
Estimated reading time: 5 minutes

Duplicate content is a major concern for content creators since it affects both a website’s traffic and its ranking on search engines. As a result, it can be harmful for any online platform. In this article, we will be sharing some tips on how to avoid duplicate content.
What is duplicate content?
As per Google’s own definition, “duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar.”
In simpler terms, duplicate content means having identical or similar content on two or more different web pages. It can be found on the same site as well as on different sites.
For search engines, duplicate content poses indexing problems. Even if Google has stated that duplicate content will not penalize your website, you still risk experiencing ranking and traffic losses. Duplicate content may lead to self-competition for the same keyword, making each page less relevant than if they were unique.
Very often, duplicate content is only the result of human or technical errors. That’s why identifying and correcting it is one of the priorities of an SEO analyst.

How to identify pages with duplicate content on your site?
Nobody knows exactly how Google evaluates when content is duplicate. However, Google has published a paper in 2007 explaining a method to “Detect Near-Duplicates for Web Crawling”.You can read all about this here. This paper describes the Simhash technique which is an algorithm used by Google to quickly identify near duplicate pages. Some crawling tools like Oncrawl have included Simhash calculation in their reporting. This allows you to identify clusters of similar pages on your website.
4 ways to avoid duplicate content
Using a txt.robot is considered by many to be the short route to preventing Google from crawling and indexing pages with duplicate content. However, Google strongly warns against this practice and instead recommends the following techniques:
Write your own content
To avoid duplicate content on your website, it is advisable to avoid using external content. Instead you should write your own content, blog posts, product descriptions or any other content that you require. In the event that you need content from an external editor, be sure to check that the content has not been copied from another website. There are several online tools, such as Kill Duplicate and the MozBar plugin, that can help you detect cross-domain or external duplicate content.
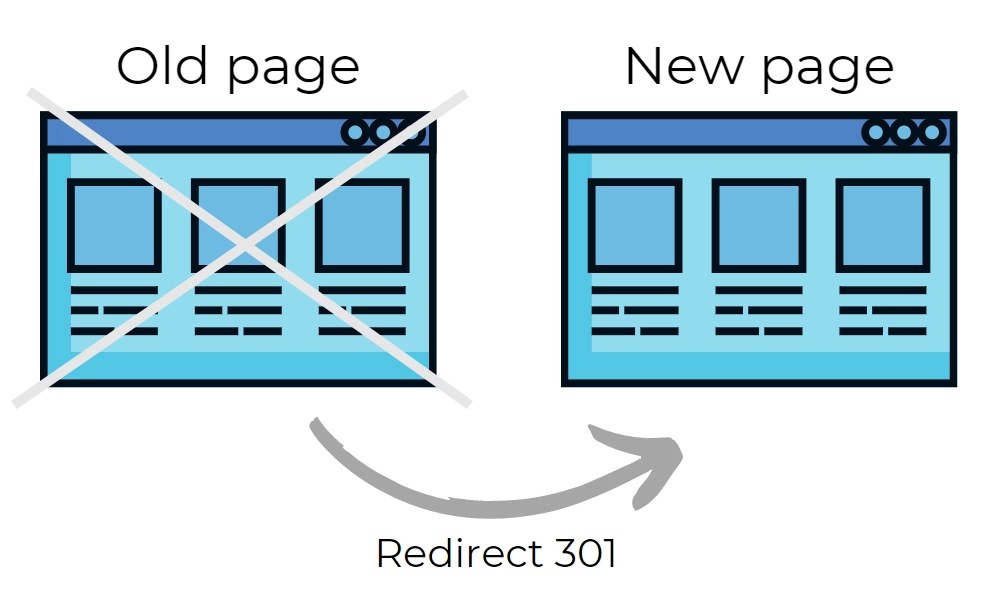
301 redirect
SEO experts recommend using 301 redirects when you have similar content on your website and want to redirect to the original URL. A 301 redirect indicates to web users and search engines that the given content has either been moved to another web address or permanently deleted. It also passes link authority to the new URL and desindexes the old URL. This is the most common method of redirection as it allows your new URL to keep the reputation of the old one.
Use a canonical tag
A canonical tag, also known as rel canonical, shows Google which reference page should be indexed in the event that several pages of the same site have duplicate content. While it allows you to redirect the link juice like a 301, it does not influence your traffic, meaning that users can still access your page.
To implement the canonical tag, you should place the tag below in the < header > part of your webpage. It takes the following form:
<link rel=”canonical” href=”https://example.com” />
Meta robots noindex
Meta robots noindex is a term used in SEO to instruct search engines not to index a particular web page. It comes into play when you have duplicate content on one or more web pages. Here’s how to implement meta robots noindex on your website:
You must set the meta robot tag in the header part of the pages to avoid indexing the pages or to deindex them. It should appear in either of the following formats:
<meta name=”robots” content=”noindex,follow”>
or,
<meta name=”robots” content=”noindex,nofollow”>
When the Googlebot reads the word “noindex” in the tag while crawling, it will understand that this page must not be indexed or should be removed from it’s index.
In case you want to remove indexed pages and you have added the “noindex” tag, be patient. It may take weeks and even months before Google crawled your page with the updated tag and followed up on this instruction.
Bottom Line
Taking the time to check if and where you have duplicate content is totally worth it. The more pages you have on your website, the more likely it is that you have duplicate content.
Needless to say if ever you need an extra helping hand to analyze your content, we will happily assist you. Our solution encompasses a series of tools that will create automatically perfect unique landing pages without any duplicate content.
About The Author
How can Verbolia help your e-commerce platform.