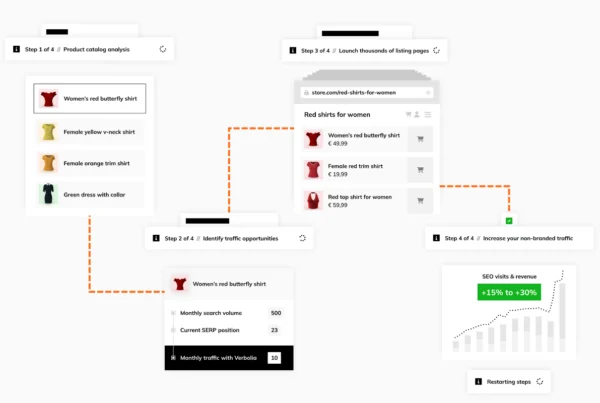
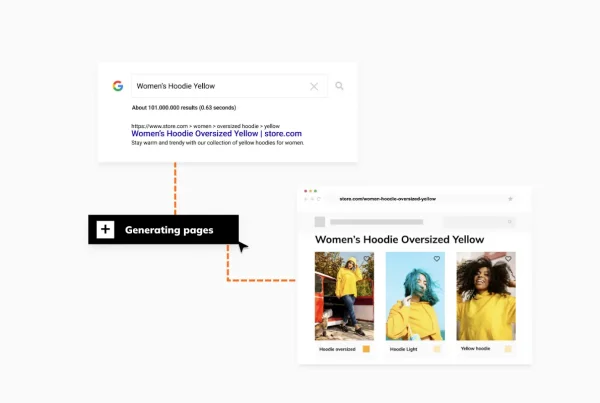
Blog article
How to Avoid Duplicate Content on Your Ecommerce Site
Estimated reading time: 6 minutes

Creating content is one of the most important components of building an ecommerce website. It’s through content that customers and prospects get to know who you are, see the available products and their descriptions, locate payment instructions, read blog posts, and more.
The very success of your site’s search engine optimization (SEO) efforts is hinged on the quality of your content. Getting content right often means steering clear of some of the more common mistakes, such as unintentionally competing against your own pages with similar keywords, a problem that tools like the Free Keyword Cannibalization Identifier can help you navigate.
One of those mistakes is duplicate content.
In this article, we define duplicate content and examine the most effective ways of avoiding it

Duplicate content occurs when part or all of one or more pages on a website appears on another page on your website or on a third-party site. Content duplication can significantly hamper the strength of your site’s SEO.
When Google’s search algorithm is determining what results to return for a specific search query, it will avoid showing any two results that contain identical or near-identical content.
It’s in the search engine’s best interest for users to see the most relevant yet unique results. So when your site has duplicate content, the affected pages risk being deprioritized or ignored completely in search results when Google determines which page is more likely to be the original.
Duplicate content is not entirely avoidable or wrong—and Google knows this. Duplicate content on different sites is not necessarily a problem—for example, if it’s syndicated content.
If you are not familiar with syndicated content, think about the results when you last ran a Google Search on a news story you were interested in. You likely found virtually identical narration of the incident on multiple news sites.
Often, the original news story was done by major agencies such as Reuters or the Associated Press then published on numerous news sites. This is a classic example of content syndication and, if done correctly, does not attract duplicate content penalty.
Still, other than correctly done syndicated content, duplicate content will harm your site by causing search engines to ignore some of your pages or, in the worst case, your entire website.
How to avoid duplicate content
So what happens when you realize your ecommerce site has duplicate content? Fortunately, most duplicate content issues can be avoided or resolved with relative ease as long as you know the technical errors responsible.
1. 301 redirects
For many websites, typing this https://www.fictionalecommercesite.com and this https:// fictionalecommercesite.com on your browser bar leads to the same page. In the background, it’s not that straightforward. Those two are actually distinct web addresses and can, therefore, be considered duplicates.
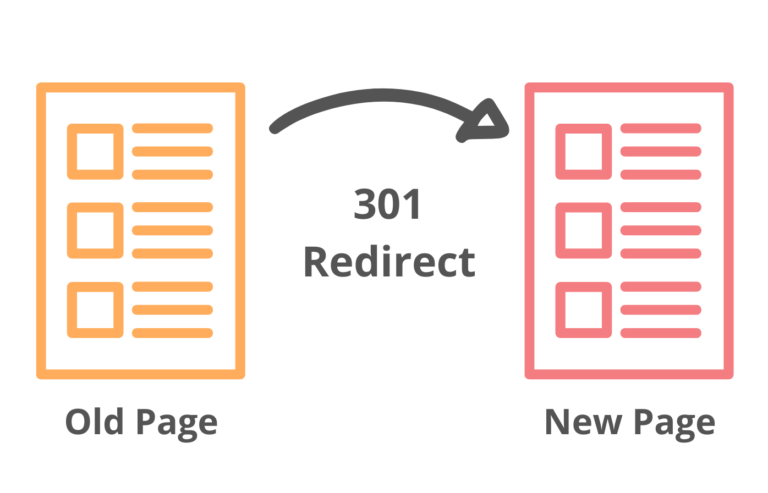
To correct this, choose one version of URL for each page on your site as the main one, and then use 301 redirects to redirect all others to that one. Note that when you apply a 301 redirect, the status of your page will change to “Moved Permanently.”
2. Canonical tags
Many people’s perception of web pages is distinct files stored on a web server. In the eyes of search engine crawlers, though, the same web page may be accessible via multiple URLs. Think about marketers who append parameters to a URL in order to make it easier to track inbound traffic by source or campaign. Google considers each URL as unique even when displaying content identical to the original URL.
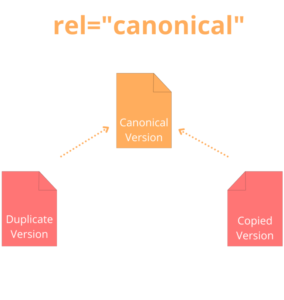
If you have two pages that have the exact same content, use canonical tags to tell search engines which one is the original. Canonical tags are page-level meta tags placed in the HTML header. They help the main page rank higher up in search results.
Note that canonical tags are also useful when you have similar pages targeting an identical keyword string. That way, Google knows which is the correct page to catalog.
3. Meta robots noindex
These tags tell search engines not to index a given page but do not prohibit them from crawling it. Put differently, you’re telling Google not to take those links into consideration for ranking purposes. That way, you avoid being penalized for duplicate pages.
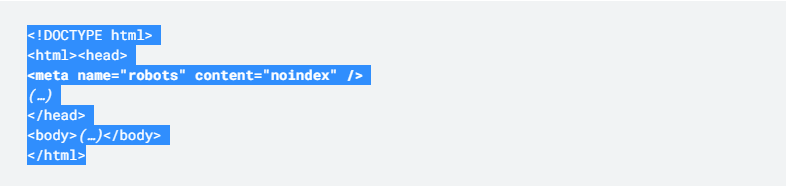
Why should you allow search engines to still crawl the page? Because Google likes access to your entire site just to confirm that everything on your website is in order. In any case, users can still access these pages.
Make the most of your ecommerce website with Verbolia
Whereas most duplicate online content is not intentional, that doesn’t negate the potentially damaging effects it could have on an ecommerce site’s SEO. Duplicate content can affect your reputation and revenue.
Tackling your site’s duplicate content issues may feel like a lot, but the long-term pay-off for your ecommerce site makes it more than worth it. So stay attentive and always keep track of how Google views your site, especially after you add new content.
Ready to see what Verbolia can do? Reach out to learn how we can help maximize your ecommerce website’s potential by publishing non-duplicate landing pages at scale.
About The Author
How can Verbolia help your e-commerce platform.